 Connect to data: Overview
Connect to data: Overview

|

|
|
|

|
|

|
Datasources and Data Assets provide an API for accessing and validating data on source data systems such as SQL-type data sources, local and remote file stores, and in-memory data frames.
Prerequisites
- Completion of the Quickstart guide
Workflow
A DatasourceProvides a standard API for accessing and interacting with data from a wide variety of source systems. provides a standard API for accessing and interacting with data from different source systems.

A Datasource provides an interface for an Execution EngineA system capable of processing data to compute Metrics. and possible external storage, and it allows Great Expectations to communicate with your source data systems.
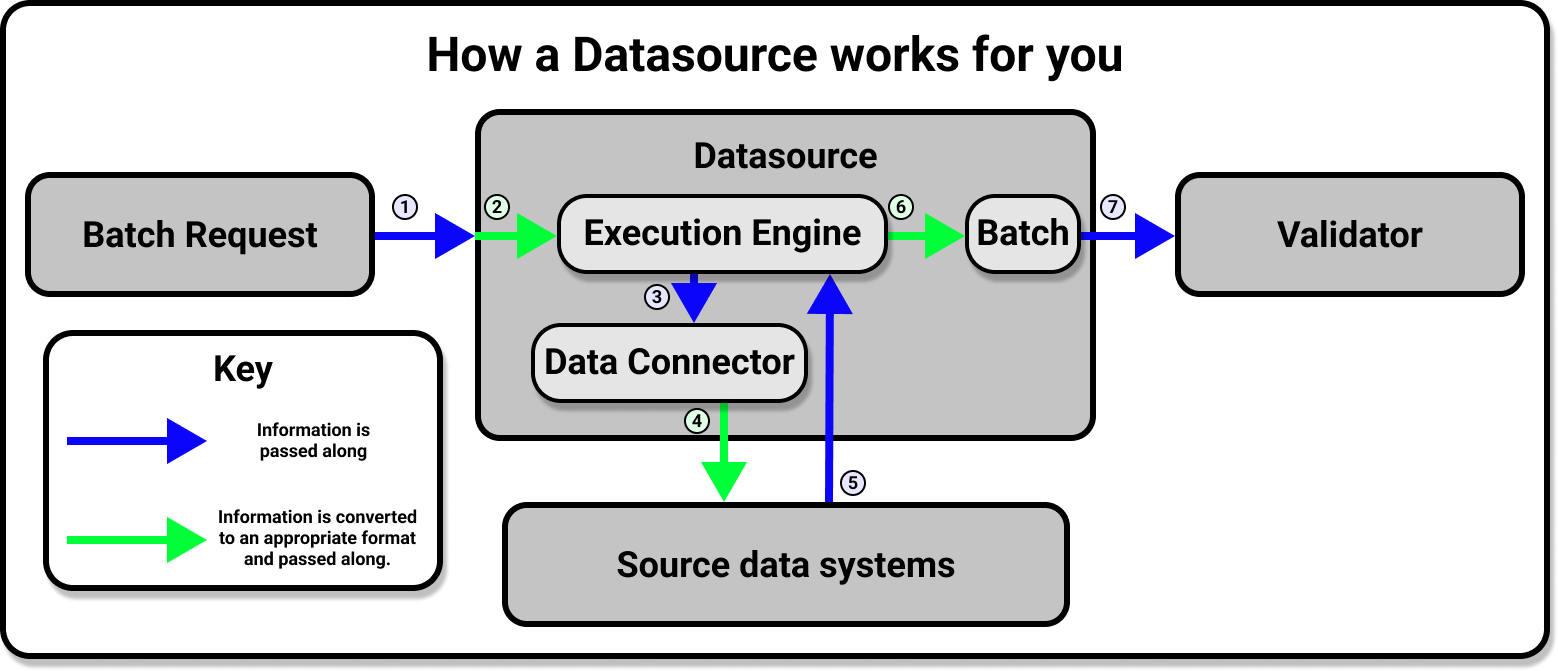
To connect to data, you add a new Datasource to your Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components. according to the requirements of your underlying data system. After you've configured your Datasource, you'll use the Datasource API to access and interact with your data, regardless of the original source systems that you use to store data.
Configure your Datasource
Your existing data systems determine how you connect to each Datasource type. To help you with your Datasource implementation, use one of the GX how-to guides for your specific use case and source data systems.
You configure a Datasource with Python and the GX Fluent Datasource API. A typical Datasource configuration appears similar to the following example:
import great_expectations as gx
context = gx.get_context()
context.sources.add_pandas_filesystem(
name="version-0.16.16 my_pandas_datasource", base_directory="./data"
)
The name key is a descriptive name for
your Datasource. The
add_<datasource> method takes the
Datasource-specific arguments that are used to
configure it. For example, the
add_pandas_filesystem takes a
base_directory argument in the previous
example, while the
context.sources.add_postgres(name, ...)
method takes a connection_string that is
used to connect to the database.
Call the add_<datasource> method in
your context to run configuration checks. For example,
it makes sure the base_directory exists
for the pandas_filesystem Datasource and
the connection_string is valid for a SQL
database.
These methods also persist your Datasource to your Data Context. The storage location for a Datasource and its reusability are determined by the Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components. type. For a File Data Context the changes are persisted to disk, for a Cloud Data Context the changes are persisted to the cloud, and for an Ephemeral Data Context the data remains in memory and don't persist beyond the current Python session.
View your Datasource configuration
The context.datasources attribute in your
Data Context allows you to access your Datasource
configuration. For example, the following command
returns the Datasource configuration:
datasource = context.datasources["my_pandas_datasource"]
print(datasource)