Data Context
A Data Context is the primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components.
As the primary entry point for all of Great
Expectations' APIs, the Data Context provides
convenience methods for accessing common objects based
on untyped input or common defaults. It also provides
the ability to easily handle configuration of its own
top-level components, and the configs and data
necessary to back up your Data Context itself can be
stored in a variety of ways. It doesn’t matter how you
instantiate your DataContext, or store
its configs: once you have the
DataContext in memory, it will always
behave in the same way.
Relationships to other objects
Your Data Context will provide you with methods to configure your Stores, plugins, and Data Docs. It will also provide the methods needed to create, configure, and access your DatasourcesProvides a standard API for accessing and interacting with data from a wide variety of source systems., ExpectationsA verifiable assertion about data., ProfilersGenerates Metrics and candidate Expectations from data., and CheckpointsThe primary means for validating data in a production deployment of Great Expectations.. In addition to all of that, it will internally manage your MetricsA computed attribute of data such as the mean of a column., Validation ResultsGenerated when data is Validated against an Expectation or Expectation Suite., and the contents of your Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc. for you!
Use Cases
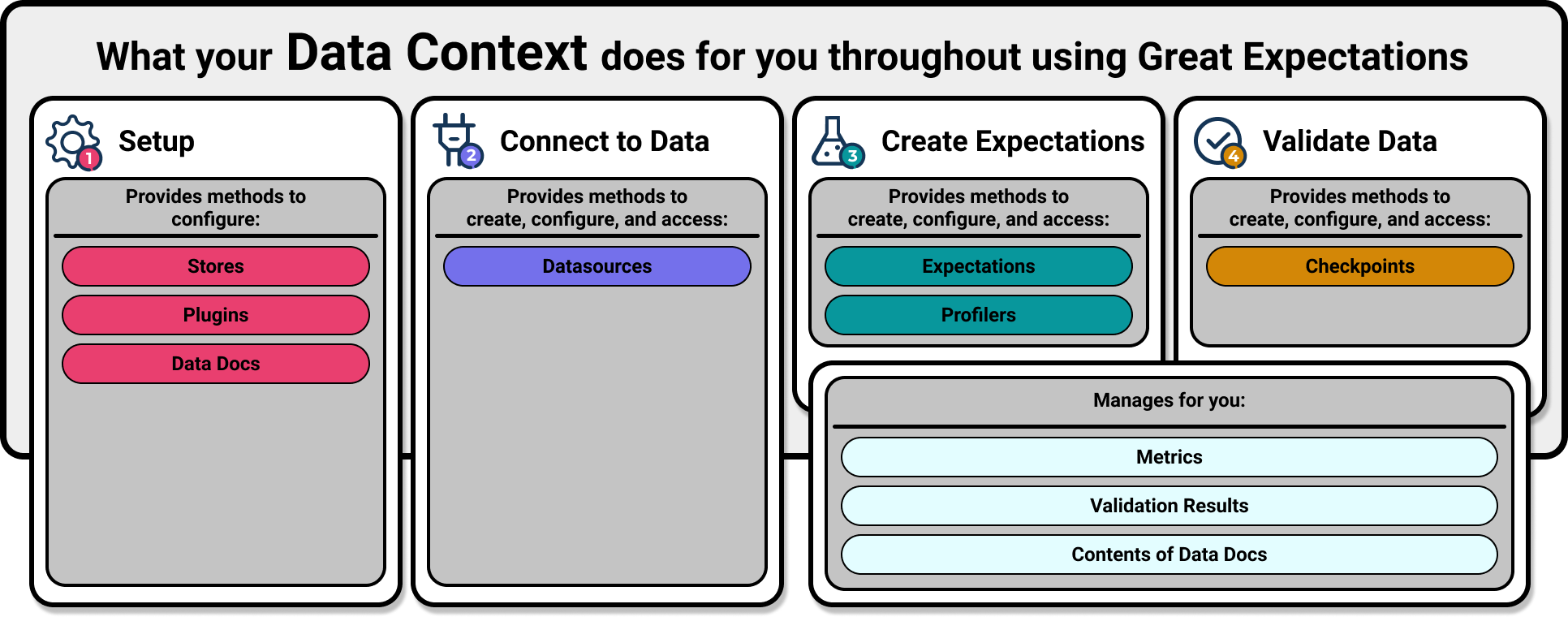
During Setup you will initialize a Data Context. For instructions on how to do this, see Setup Overview: Initialize a Data Context documentation. For more information on configuring a newly initialized Data Context, see guides for configuring your Data Context.
You can also use the Data Context to manage optional configurations for your Stores, Plugins, and Data Docs. For information on configuring Stores, please check out our guides for configuring stores. For Data Docs, please reference our guides on configuring Data Docs.
When connecting to Data, your Data Context will be used to create and configure Datasources. For more information on how to create and configure Datasources, see overview documentation for the Connect to Data step, as well as our how-to guides for connecting to data.
When creating Expectations, your Data Context will be used to create Expectation SuitesA collection of verifiable assertions about data. and Expectations, as well as save them to an Expectations StoreA connector to store and retrieve information about collections of verifiable assertions about data.. The Data Context also provides your starting point for creating Custom Profilers, and will manage the Metrics and Validation Results involved in running a Profiler automatically. Finally, the Data Context will manage the content of your Data Docs (displaying such things as the Validation Results and Expectations generated by a Profiler) for you. For more information on creating Expectations, see overview documentation for the Create Expectations step, as well as our how-to guides for creating Expectations.
When Validating data, the Data Context provides your entry point for creating, configuring, saving, and accessing Checkpoints. For more information on using your Data Context to create a Checkpoint, see overview documentation for the Validate Data step.
Additionally, it continues to manage all the same behind the scenes activity involved in using Metrics, saving Validation Results, and creating the contents of your Data Docs for you.
Access to APIs
The Data Context provides a primary entry point to all of Great Expectations' APIs. Your Data Context will provide convenience methods for accessing common objects. While internal workflows of Great Expectations are strongly typed, the convenience methods available from the Data Context are exceptions, allowing access based on untyped input or common defaults.
Configuration management
A Data Context includes basic create, read, update, and delete (CRUD) operations for the core components of a Great Expectations deployment. This includes Datasources, Expectation Suites, and Checkpoints. In addition, a Data Context allows you to access and integrate Data Docs, Stores, Plugins, and so on.
Component management and config storage
The Data Context doesn't just give you convenient ways to access and configure components. It also provides the ability to create top-level components such as Datasources, Checkpoints, and Expectation Suites and manage where the information about those components is stored.
For production deployments you will want to define these components according to your source data systems and production environment. This may include storing information about those components in something other than your local environment. You can see several soup-to-nuts examples of how to do this for specific environments and source data systems in the Reference Architecture guides.
If the exact deployment pattern you want to follow isn't documented in a Reference Architecture, you can see details for configuring specific components that component's related how-to guides.
Great Expectations Cloud compatability
Because your Data Context contains the entirety of your Great Expectations project, Great Expectations Cloud can reference it to permit seamless upgrading from open source Great Expectations to Great Expectations Cloud.
Instantiating a DataContext
As a Great Expectations user, once you have created a
Data Context, you will almost always start future work
either by using
CLICommand Line Interface
commands from your Data Context's root folder, or
by instantiating a DataContext in Python:
context = gx.get_context()
Alternatively, you can use the
context_root_dir parameter if you want to
specify a specific directory
If you’re using Great Expectations Cloud, you’d set up
cloud environment variables before calling
get_context.
That’s it! You now have access to all the goodness of a DataContext.
Untyped inputs
The code standards for Great Expectations strive for strongly typed inputs. However, the Data Context's convenience functions are a noted exception to this standard. For example, to get a Batch with typed input, you could follow these steps:
from great_expectations.core.batch import BatchRequest, RuntimeBatchRequest
batch = context.get_batch(batch_request=batch_request)
However, we can take some of the friction out of that process by allowing untyped inputs:
data_asset_name = "version-0.16.16 <your_data_asset_name>"
context.get_batch(
datasource_name="version-0.16.16 taxi_datasource",
data_connector_name="version-0.16.16 default_inferred_data_connector_name",
data_asset_name=data_asset_name,
)
In this example, the get_batch() method
takes on the responsibility for inferring your
intended types, and passing it through to the correct
internal methods.
This distinction around untyped inputs reflects an
important architecture decision within the Great
Expectations codebase: “Internal workflows are
strongly typed, but we make exceptions for a handful
of convenience methods on the
DataContext.”
Stronger type-checking allows the building of cleaner code, with stronger guarantees and a better understanding of error states. It also allows us to take advantage of tools like static type checkers, cyclometric complexity analysis, etc.
However, requiring typed inputs creates a steep
learning curve for new users. For example, the first
method above can be intimidating if you haven’t done a
deep dive on exactly what a
BatchRequest is. It also requires you to
know that a Batch Request is imported from
great_expectations.core.batch.
Allowing untyped inputs makes it possible to get started much more quickly in Great Expectations. However, the risk is that untyped inputs will lead to confusion. To head off that risk, we follow the following principles:
- Type inference is conservative. If inferring types would require guessing, the method will instead throw an error.
- We raise informative errors, to help users zero in on alternative input that does not require guessing to infer.