How to Use Great Expectations with Google Cloud Platform and BigQuery
This guide will help you integrate Great Expectations (GX) with Google Cloud Platform (GCP) using our recommended workflow.
Prerequisites
- Completed the Quickstart guide
- A working local installation of Great Expectations version 0.13.49 or later.
- Familiarity with Google Cloud Platform features and functionality.
- Have completed the set-up of a GCP project with a running Google Cloud Storage container that is accessible from your region, and read/write access to a BigQuery database if this is where you are loading your data.
- Access to a GCP Service Account with permission to access and read objects in Google Cloud Storage, and read/write access to a BigQuery database if this is where you are loading your data.
Currently, Great Expectations will only install in Composer 1 and Composer 2 environments with the following packages pinned.
[tornado]==6.2
[nbconvert]==6.4.5
[mistune]==0.8.4
We are currently investigating ways to provide a smoother deployment experience in Google Composer, and will have more updates soon.
We recommend that you use Great Expectations in GCP by using the following services:
- Google Cloud Composer (GCC) for managing workflow orchestration including validating your data. GCC is built on Apache Airflow.
- BigQuery or files in Google Cloud Storage (GCS) as your DatasourceProvides a standard API for accessing and interacting with data from a wide variety of source systems.
- GCS for storing metadata (Expectation SuitesA collection of verifiable assertions about data., Validation ResultsGenerated when data is Validated against an Expectation or Expectation Suite., Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc.)
- Google App Engine (GAE) for hosting and controlling access to Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc..
We also recommend that you deploy Great Expectations to GCP in two steps:
- Developing a local configuration for GX that uses GCP services to connect to your data, store Great Expectations metadata, and run a Checkpoint.
- Migrating the local configuration to Cloud Composer so that the workflow can be orchestrated automatically on GCP.
The following diagram shows the recommended components for a Great Expectations deployment in GCP:
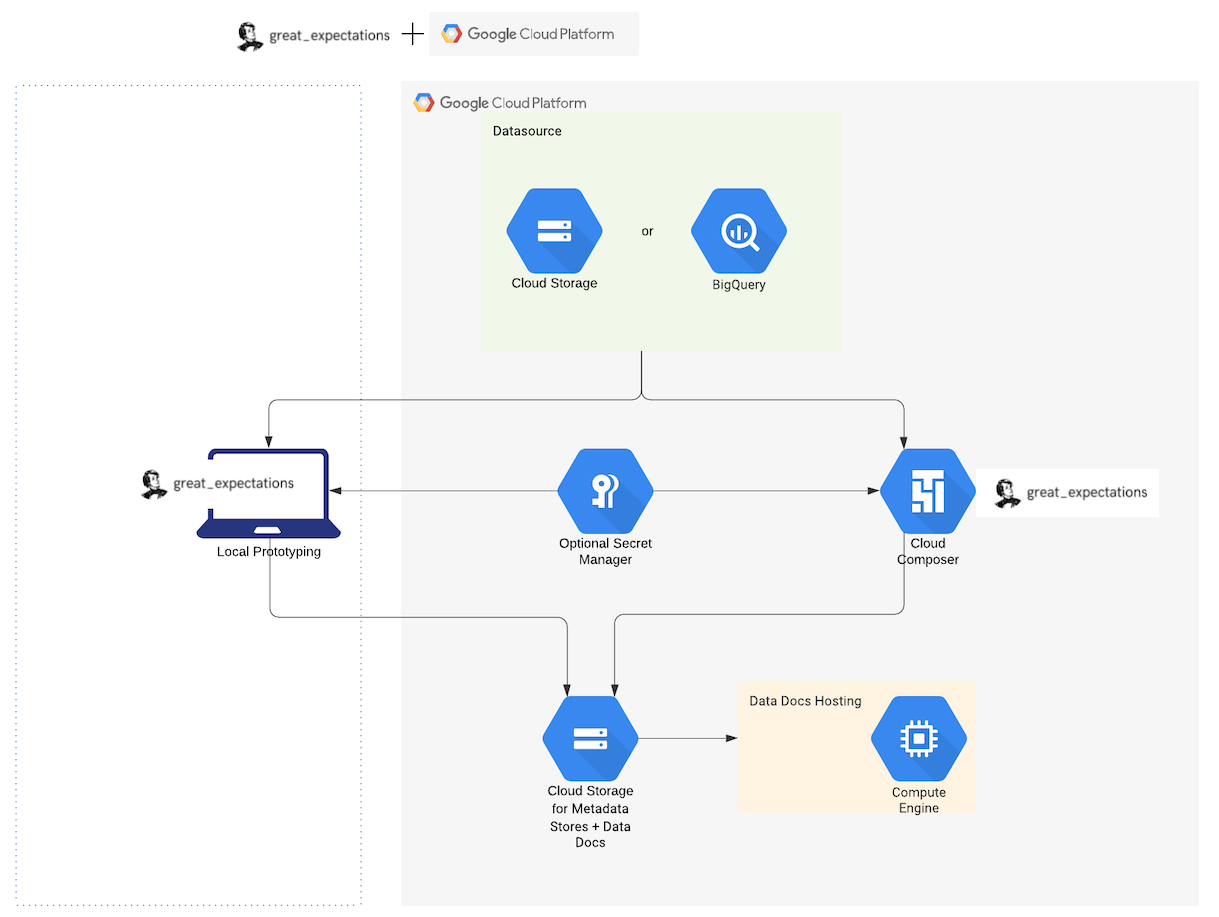
Relevant documentation for the components can also be found here:
- How to configure an Expectation store to use GCS
- How to configure a Validation Result store in GCS
- How to host and share Data Docs on GCS
- Optionally, you can also use a Secret Manager for GCP Credentials
Part 1: Local Configuration of Great Expectations that connects to Google Cloud Platform
1. If necessary, upgrade your Great Expectations version
The current guide was developed and tested using Great Expectations 0.13.49. Please ensure that your current version is equal or newer than this.
A local installation of Great Expectations can be
upgraded using a simple
pip install command with the
--upgrade flag.
pip install great-expectations --upgrade
2. Get DataContext:
One way to create a new
Data ContextThe primary entry point for a Great Expectations
deployment, with configurations and methods for
all supporting components.
is by using the create() method.
From a Notebook or script where you want to deploy
Great Expectations run the following command. Here the
full_path_to_project_directory can be an
empty directory where you intend to build your Great
Expectations configuration.
import great_expectations as gx
context = gx.data_context.FileDataContext.create(full_path_to_project_directory)
3. Connect to Metadata Stores on GCP
The following sections describe how you can take a basic local configuration of Great Expectations and connect it to Metadata stores on GCP.
The full configuration used in this guide can be found
in the
great-expectations repository
and is also linked at the bottom of this document.
When specifying prefix values for
Metadata Stores in GCS, please ensure that a
trailing slash / is not included (ie
prefix: my_prefix/ ). Currently this
creates an additional folder with the name
/ and stores metadata in the
/ folder instead of
my_prefix.
Add Expectations Store
By default, newly profiled Expectations are stored in
JSON format in the
expectations/ subdirectory of your
great_expectations/ folder. A new
Expectations Store can be configured by adding the
following lines into your
great_expectations.yml file, replacing
the project, bucket and
prefix with your information.
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
expectations_store_name: expectations_store
Great Expectations can then be configured to use this
new Expectations Store,
expectations_GCS_store, by setting the
expectations_store_name value in the
great_expectations.yml file.
stores:
expectations_GCS_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
prefix: <your>
expectations_store_name: expectations_GCS_store
For additional details and example configurations, please refer to How to configure an Expectation store to use GCS.
Add Validations Store
By default, Validations are stored in JSON format in
the uncommitted/validations/ subdirectory
of your great_expectations/ folder. A new
Validations Store can be configured by adding the
following lines into your
great_expectations.yml file, replacing
the project, bucket and
prefix with your information.
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
validations_store_name: validations_store
Great Expectations can then be configured to use this
new Validations Store,
validations_GCS_store, by setting the
validations_store_name value in the
great_expectations.yml file.
stores:
validations_GCS_store:
class_name: ValidationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
prefix: <your>
validations_store_name: validations_GCS_store
For additional details and example configurations, please refer to How to configure an Validation Result store to use GCS.
Add Data Docs Store
To host and share Datadocs on GCS, we recommend using the following guide, which will explain how to host and share Data Docs on Google Cloud Storage using IP-based access.
Afterwards, your
great-expectations.yml will contain the
following configuration under
data_docs_sites, with
project, and bucket being
replaced with your information.
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
gs_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
site_index_builder:
class_name: DefaultSiteIndexBuilder
You should also be able to view the deployed DataDocs site by running the following CLI command:
gcloud app browse
If successful, the gcloud CLI will
provide the URL to your app and launch it in a new
browser window, and you should be able to view the
index page of your Data Docs site.
4. Connect to your Data
The remaining sections in Part 1 contain descriptions of how to connect to your data in Google Cloud Storage (GCS) or BigQuery and build a CheckpointThe primary means for validating data in a production deployment of Great Expectations. that you'll migrate to Google Cloud Composer.
More details can be found in the corresponding How to Guides, which have been linked.
- Data in GCS
- Data in BigQuery
Using the
Data ContextThe primary entry point for a Great
Expectations deployment, with configurations
and methods for all supporting
components.
that was initialized in the previous section,
add the name of your GCS bucket to the
add_pandas_gcs function.
datasource = context.sources.add_pandas_gcs(
name="gcs_datasource", bucket_or_name="version-0.16.16 test_docs_data"
)
In the example, we have added a Datasource that
connects to data in GCS using a Pandas
dataframe. The name of the new datasource is
gcs_datasource and it refers to a
GCS bucket named test_docs_data.
For more details on how to configure the Datasource, and additional information on authentication, please refer to How to connect to data on GCS using Pandas
In order to support tables that are created as the result of queries in BigQuery, Great Expectations previously asked users to define a named permanent table to be used as a "temporary" table that could later be deleted, or set to expire by the database. This is no longer the case, and Great Expectations will automatically set tables that are created as the result of queries to expire after 1 day.
Using the Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components. that was initialized in the previous section, create a Datasource that will connect to data in BigQuery,
datasource = context.sources.add_or_update_sql(
name="version-0.16.16 my_bigquery_datasource",
connection_string="bigquery://<gcp_project_name>/<bigquery_dataset>",
)
In the example, we have created a Datasource
named my_bigquery_datasource, using
the add_or_update_sql method and
passing in a connection string.
To configure the BigQuery Datasource, see How to connect to a BigQuery database.
4. Create Assets
- Data in GCS
- Data in BigQuery
Add a CSV Asset to your
Datasource by using the
add_csv_asset function.
First, configure the prefix and
batching_regex. The
prefix is for the path in the GCS
bucket where we can find our files. The
batching_regex is a regular
expression that indicates which files to treat
as Batches in the Asset, and how to identify
them.
batching_regex = r"yellow_tripdata_sample_(?P<year>\d{4})-(?P<month>\d{2})\.csv"
prefix = "data/taxi_yellow_tripdata_samples/"
In our example, the pattern
r"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_(?P<year>\d{4})-(?P<month>\d{2})\.csv"
is intended to build a Batch for each file in
the GCS bucket, which are:
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01.csv
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-02.csv
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-03.csv
The batching_regex pattern will
match the 4 digits of the year portion and
assign it to the year domain, and
match the 2 digits of the month portion and
assign it to the month domain.
Next we can add an Asset named
csv_taxi_gcs_asset to our
Datasource by using the
add_csv_asset function.
data_asset = datasource.add_csv_asset(
name="version-0.16.16 csv_taxi_gcs_asset", batching_regex=batching_regex, gcs_prefix=prefix
)
Add a BigQuery Asset into your
Datasource either as a table asset
or query asset.
In the first example, a table
Asset named
my_table_asset is built by naming
the table in our BigQuery Database, which is
taxi_data in our case.
table_asset = datasource.add_table_asset(name="my_table_asset", table_name="version-0.16.16 taxi_data")
In the second example, a query
Asset named
my_query_asset is built by
submitting a query to the same table
taxi_data. Although we are showing
a simple operation here, the query can be
arbitrarily complicated, including any number of
JOIN,
SELECT operations and subqueries.
query_asset = datasource.add_query_asset(
name="version-0.16.16 my_query_asset", query="SELECT * from taxi_data"
)
5. Get Batch and Create ExpectationSuite
- Data in GCS
- Data in BigQuery
For our example, we will be creating an
ExpectationSuite with
instant feedback from a sample Batch of
data, which we will describe in our
BatchRequest. For additional
examples on how to create ExpectationSuites,
either through
domain knowledge
or using a DataAssistant or a Custom Profiler,
please refer to the documentation under
How to Guides ->
Creating and editing Expectations for your
data
-> Core skills.
First create an ExpectationSuite by using the
add_or_update_expectation_suite
method on our DataContext. Then use it to get a
Validator.
context.add_or_update_expectation_suite(expectation_suite_name="version-0.16.16 test_gcs_suite")
validator = context.get_validator(
batch_request=batch_request, expectation_suite_name="version-0.16.16 test_gcs_suite"
)
Next, use the Validator to run
expectations on the batch and automatically add
them to the ExpectationSuite. For our example,
we will add
expect_column_values_to_not_be_null
and
expect_column_values_to_be_between
(passenger_count and
congestion_surcharge are columns in
our test data, and they can be replaced with
columns in your data).
validator.expect_column_values_to_not_be_null(column="passenger_count")
validator.expect_column_values_to_be_between(
column="congestion_surcharge", min_value=-3, max_value=1000
)
Lastly, save the ExpectationSuite, which now contains our two Expectations.
validator.save_expectation_suite(discard_failed_expectations=False)
For more details on how to configure the RuntimeBatchRequest, as well as an example of how you can load data by specifying a GCS path to a single CSV, please refer to How to connect to data on GCS using Pandas
For our example, we will be creating our
ExpectationSuite with
instant feedback from a sample Batch of
data, which we will describe in our
RuntimeBatchRequest. For additional
examples on how to create ExpectationSuites,
either through
domain knowledge
or using a DataAssistant or a Custom Profiler,
please refer to the documentation under
How to Guides ->
Creating and editing Expectations for your
data
-> Core skills.
Using the table_asset from the
previous step, build a
BatchRequest.
request = table_asset.build_batch_request()
Next, create an ExpectationSuite by using the
add_or_update_expectation_suite
method on our DataContext. Then use it to get a
Validator.
context.add_or_update_expectation_suite(expectation_suite_name="version-0.16.16 test_bigquery_suite")
validator = context.get_validator(
batch_request=request, expectation_suite_name="version-0.16.16 test_bigquery_suite"
)
Next, use the Validator to run
expectations on the batch and automatically add
them to the ExpectationSuite. For our example,
we will add
expect_column_values_to_not_be_null
and
expect_column_values_to_be_between
(passenger_count and
congestion_surcharge are columns in
our test data, and they can be replaced with
columns in your data).
validator.expect_column_values_to_not_be_null(column="passenger_count")
validator.expect_column_values_to_be_between(
column="congestion_surcharge", min_value=0, max_value=1000
)
Lastly, save the ExpectationSuite, which now contains our two Expectations.
validator.save_expectation_suite(discard_failed_expectations=False)
To configure the BatchRequest and learn how you can load data by specifying a table name, see How to connect to a BigQuery database
5. Build and Run a Checkpoint
For our example, we will create a basic Checkpoint
configuration using the
SimpleCheckpoint class. For
additional examples, information on
how to add validations, data, or suites to existing
checkpoints, and
more complex configurations
please refer to the documentation under
How to Guides ->
Validating your data ->
Checkpoints.
- Data in GCS
- Data in BigQuery
Add the following Checkpoint
gcs_checkpoint to the DataContext.
Here we are using the same
BatchRequest and
ExpectationSuite name that we used
to create our Validator above.
checkpoint = gx.checkpoint.SimpleCheckpoint(
name="version-0.16.16 gcs_checkpoint",
data_context=context,
validations=[
{"batch_request": batch_request, "expectation_suite_name": "test_gcs_suite"}
],
)
Next, you can run the Checkpoint directly
in-code by calling
checkpoint.run().
checkpoint_result = checkpoint.run()
At this point, if you have successfully configured the local prototype, you will have the following:
-
An ExpectationSuite in the GCS bucket
configured in
expectations_GCS_store(ExpectationSuite is namedtest_gcs_suitein our example). -
A new Validation Result in the GCS bucket
configured in
validation_GCS_store. -
Data Docs in the GCS bucket configured in
gs_sitethat is accessible by runninggcloud app browse.
Now you are ready to migrate the local configuration to Cloud Composer.
Add the following Checkpoint
bigquery_checkpoint to the
DataContext. Here we are using the same
BatchRequest and
ExpectationSuite name that we used
to create our Validator above.
checkpoint = gx.checkpoint.SimpleCheckpoint(
name="version-0.16.16 bigquery_checkpoint",
data_context=context,
validations=[
{"batch_request": request, "expectation_suite_name": "test_bigquery_suite"}
],
)
Next, you can run the Checkpoint directly
in-code by calling
checkpoint.run().
checkpoint_result = checkpoint.run()
At this point, if you have successfully configured the local prototype, you will have the following:
-
An ExpectationSuite in the GCS bucket
configured in
expectations_GCS_store(ExpectationSuite is namedtest_bigquery_suitein our example). -
A new Validation Result in the GCS bucket
configured in
validation_GCS_store. -
Data Docs in the GCS bucket configured in
gs_sitethat is accessible by runninggcloud app browse.
Now you are ready to migrate the local configuration to Cloud Composer.
Part 2: Migrating our Local Configuration to Cloud Composer
We will now take the local GX configuration from Part 1 and migrate it to a Cloud Composer environment so that we can automate the workflow.
There are a number of ways that Great Expectations can be run in Cloud Composer or Airflow.
-
Running a Checkpoint in Airflow using a
bash operator -
Running a Checkpoint in Airflow using a
python operator -
Running a Checkpoint in Airflow using a
Airflow operator
For our example, we are going to use the
bash operator to run the Checkpoint. This
portion of the guide can also be found in the
following
Walkthrough Video.
1. Create and Configure a Service Account
Create and configure a Service Account on GCS with the appropriate privileges needed to run Cloud Composer. Please follow the steps described in the official Google Cloud documentation to create a Service Account on GCP.
In order to run Great Expectations in a Cloud Composer environment, your Service Account will need the following privileges:
Composer WorkerLogs ViewerLogs WriterStorage Object CreatorStorage Object Viewer
If you are accessing data in BigQuery, please ensure your Service account also has privileges for:
BigQuery Data EditorBigQuery Job UserBigQuery Read Session User
2. Create Cloud Composer environment
Create a Cloud Composer environment in the project you will be running Great Expectations. Please follow the steps described in the official Google Cloud documentation to create an environment that is suited for your needs.
The current Deployment Guide was developed and tested in Great Expectations 0.13.49, Composer 1.17.7 and Airflow 2.0.2. Please ensure your Environment is equivalent or newer than this configuration.
3. Install Great Expectations in Cloud Composer
Installing Python dependencies in Cloud Composer can
be done through the Composer web Console
(recommended), gcloud or through a REST
query. Please follow the steps described in
Installing Python dependencies in Google Cloud
to install great-expectations in Cloud
Composer. If you are connecting to data in BigQuery,
please ensure sqlalchemy-bigquery is also
installed in your Cloud Composer environment.
If you run into trouble while installing Great Expectations in Cloud Composer, the official Google Cloud documentation offers the following guide on troubleshooting PyPI package installations.
4. Move local configuration to Cloud Composer
Cloud Composer uses Cloud Storage to store Apache
Airflow DAGs (also known as workflows), with each
Environment having an associated Cloud Storage bucket
(typically the name of the bucket will follow the
pattern
[region]-[composer environment
name]-[UUID]-bucket).
The simplest way to perform the migration is to move
the entire local
great_expectations/ folder from
Part 1
to the Cloud Storage bucket where Composer can access
the configuration.
First open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page. In the Configuration tab, the name of the Cloud Storage bucket can be found to the right of the DAGs folder.
This will take you to the folder where DAGs are
stored, which can be accessed from the Airflow worker
nodes at: /home/airflow/gcsfuse/dags. The
location we want to uploads
great_expectations/ is
one level above the
/dags folder.
Upload the local
great_expectations/ folder either
dragging and dropping it into the window, using
gsutil cp, or by clicking the
Upload Folder button.
Once the great_expectations/ folder is
uploaded to the Cloud Storage bucket, it will be
mapped to the Airflow instances in your Cloud Composer
and be accessible from the Airflow Worker nodes at the
location:
/home/airflow/gcsfuse/great_expectations.
5. Write DAG and Add to Cloud Composer
- Data in GCS
- Data in BigQuery
We will create a simple DAG with a single node
(t1) that runs a
BashOperator, which we will store
in a file named:
ge_checkpoint_gcs.py.
from datetime import timedelta
import airflow
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
"start_date": airflow.utils.dates.days_ago(0),
"retries": 1,
"retry_delay": timedelta(days=1),
}
dag = DAG(
"GX_checkpoint_run",
default_args=default_args,
description="running GX checkpoint",
schedule_interval=None,
dagrun_timeout=timedelta(minutes=5),
)
# priority_weight has type int in Airflow DB, uses the maximum.
t1 = BashOperator(
task_id="checkpoint_run",
bash_command="(cd /home/airflow/gcsfuse/great_expectations/ ; great_expectations checkpoint run gcs_checkpoint ) ",
dag=dag,
depends_on_past=False,
priority_weight=2**31 - 1,
)
The BashOperator will first change
directories to
/home/airflow/gcsfuse/great_expectations, where we have uploaded our local
configuration. Then we will run the Checkpoint
using same CLI command we used to run the
Checkpoint locally:
great_expectations checkpoint run gcs_checkpoint
To add the DAG to Cloud Composer, move
ge_checkpoint_gcs.py to the
environment's DAGs folder in Cloud Storage.
First, open the Environments page in the Cloud
Console, then click on the name of the
environment to open the Environment details
page.
On the Configuration tab, click on the name of the Cloud Storage bucket that is found to the right of the DAGs folder. Upload the local copy of the DAG you want to upload.
For more details, please consult the official documentation for Cloud Composer
We will create a simple DAG with a single node
(t1) that runs a
BashOperator, which we will store
in a file named:
ge_checkpoint_bigquery.py.
from datetime import timedelta
import airflow
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
"start_date": airflow.utils.dates.days_ago(0),
"retries": 1,
"retry_delay": timedelta(days=1),
}
dag = DAG(
"GX_checkpoint_run",
default_args=default_args,
description="running GX checkpoint",
schedule_interval=None,
dagrun_timeout=timedelta(minutes=5),
)
# priority_weight has type int in Airflow DB, uses the maximum.
t1 = BashOperator(
task_id="checkpoint_run",
bash_command="(cd /home/airflow/gcsfuse/great_expectations/ ; great_expectations checkpoint run bigquery_checkpoint ) ",
dag=dag,
depends_on_past=False,
priority_weight=2**31 - 1,
)
The BashOperator will first change
directories to
/home/airflow/gcsfuse/great_expectations, where we have uploaded our local
configuration. Then we will run the Checkpoint
using same CLI command we used to run the
Checkpoint locally:
great_expectations checkpoint run bigquery_checkpoint
To add the DAG to Cloud Composer, move
ge_checkpoint_bigquery.py to the
environment's DAGs folder in Cloud Storage.
First, open the Environments page in the Cloud
Console, then click on the name of the
environment to open the Environment details
page.
On the Configuration tab, click on the name of the Cloud Storage bucket that is found to the right of the DAGs folder. Upload the local copy of the DAG you want to upload.
For more details, please consult the official documentation for Cloud Composer
6. Run DAG / Checkpoint
Now that the DAG has been uploaded, we can trigger the DAG using the following methods:
- Trigger the DAG manually.
- Trigger the DAG on a schedule, which we have set to be once-per-day in our DAG
- Trigger the DAG in response to events.
In order to trigger the DAG manually, first open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page. In the Airflow webserver column, follow the Airflow link for your environment. This will open the Airflow web interface for your Cloud Composer environment. In the interface, click on the Trigger Dag button on the DAGs page to run your DAG configuration.
7. Check that DAG / Checkpoint has run successfully
If the DAG run was successful, we should see the
Success status appear on the DAGs page of
the Airflow Web UI. We can also check so check that
new Data Docs have been generated by accessing the URL
to our gcloud app.
8. Congratulations!
You've successfully migrated your Great Expectations configuration to Cloud Composer!
There are many ways to iterate and improve this
initial version, which used a
bash operator for simplicity. For
information on more sophisticated ways of triggering
Checkpoints, building our DAGs, and dividing our Data
Assets into Batches using DataConnectors, please refer
to the following documentation:
-
How to run a Checkpoint in Airflow using a
python operator. -
How to run a Checkpoint in Airflow using a
Great Expectations Airflow operator(recommended). - How to trigger the DAG on a schedule.
- How to trigger the DAG on a schedule.
- How to trigger the DAG in response to events.
- How to use the Google Kubernetes Engine (GKE) to deploy, manage and scale your application.
- How to configure a DataConnector to introspect and partition tables in SQL.
- How to configure a DataConnector to introspect and partition a file system or blob store.
Also, the following scripts and configurations can be found here:
-
Local GX configuration used in this guide can be
found in the
great-expectationsGIT repository. - Script to test BigQuery configuration.
- Script to test GCS configuration.